THE NARRATIVE KNOCKDOWN 2: Richard Horton (Editor-in-Chief, The Lancet) vs Narrative Hercules (plus we add the second narrative metric, the AF)
As we continue to work on the interpretation of our narrative metrics, it’s clear another major editor pales in comparison to Narrative Hercules.


First off, the second index
Last week we introduced the NI (Narrative Index, which is just the BUTs / ANDs ratio). This week we add the other metric — the AF (AND Frequency, which is the percentage of all words in a text that are AND).
You can read a great deal about both metrics in our new book Lincoln But Trump. In it, we present the famous Lincoln-Douglas Debates of 1858 as the founding data set for the NI, along with a study of the World Bank Annual Reports as the founding data set for the AF.
The unique thing about the AF is it has a very clear optimum value of 2.5%. To learn a bunch about this just ask Chat GPT (though as usual, some of what it will tell you will be wrong). For the definitive explanation of why we stick with 2.5% definitely read the book.
Also, if you’re really interested in this topic get Chat GPT to tell you about POLYSYNDETON (what Hemingway often did) and PARATAXIS (the use of short, punchy, staccato style).
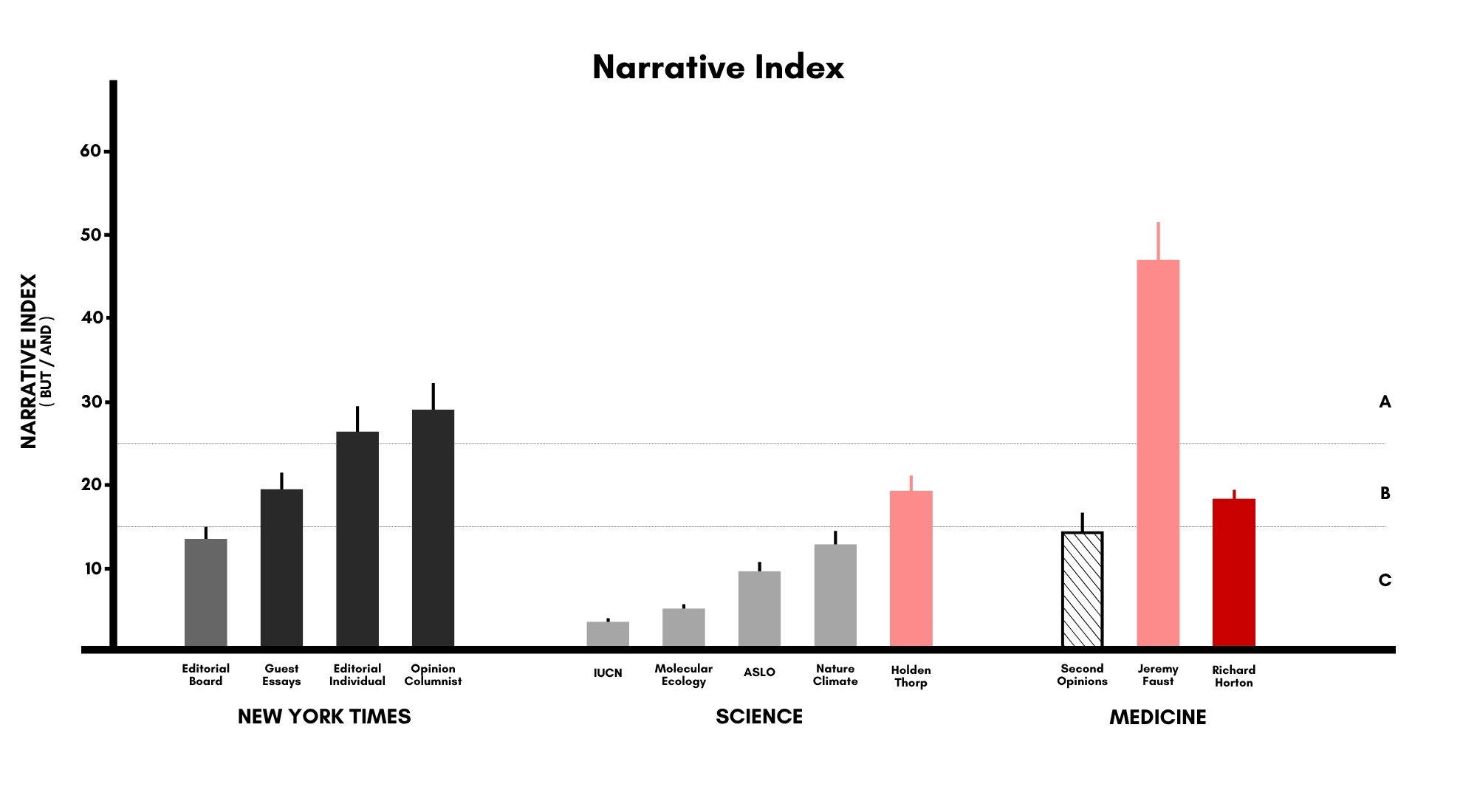
The Data: Another one bites the narrative dust
First, the data. As you can see, Richard Horton, Editor-in-Chief of The Lancet, scores very similar to last week’s contender, . They scored 18 and 20, respectively for the NI, and 2.8 and 3.0 for the AF.
BUT … as far as the numbers go, neither is in the same realm as our Narrative Hercules, . His NI scores are more than double theirs. DOUBLE. Which continues to baffle us.
What does it all mean?
Yep. That’s the relevant question. There’s no arguing with the data. The numbers are shockingly simple; the patterns are clear and significant.
But what exactly does it mean?
We’re not entirely certain ourselves. But we think it's important to look at the New York Times professional columnists.
Look at the NI average of these big-time professionals (Dowd, Kristof, Friedman, etc.). They provide the most important reference point. They are the standard against which to measure everyone. They are the ones who know how to argue most powerfully, most compellingly, most persuasively.
The editors of both Science and The Lancet are not in the same range. Which makes you think it’s a difference of worlds between the broad societal dynamics addressed in the NY Times versus the more specific disciplines of science or medicine.
BUT THEN … once again … what about the exception? Dr. Faust.
That’s where our thinking is at the moment.
THEREFORE … tune in next week for Round 3 of THE NARRATIVE KNOCKDOWN!